correlation <- 0.5
alpha <- 0.05
trials <- 1000
results <- tibble(n = seq(10, 100, by = 5)) |>
mutate(
sims = map(n, \(n) {
tibble(trial = 1:trials) |>
mutate(
data = map(trial, \(t) {
MASS::mvrnorm(n, mu = c(0, 0),
Sigma = matrix(c(1, correlation, correlation, 1), 2, 2)) |>
as_tibble(.name_repair = ~c("happiness", "optimism"))
}),
p_value = map_dbl(data, \(d) cor.test(d$happiness, d$optimism)$p.value)
)
}),
achieved_power = map_dbl(sims, \(s) mean(s$p_value < alpha))
) |>
select(n, achieved_power)Monte Carlo Simulation
EPH 752 Advanced Research Methods
Let’s Try It with a Chess Set

Watching Convergence
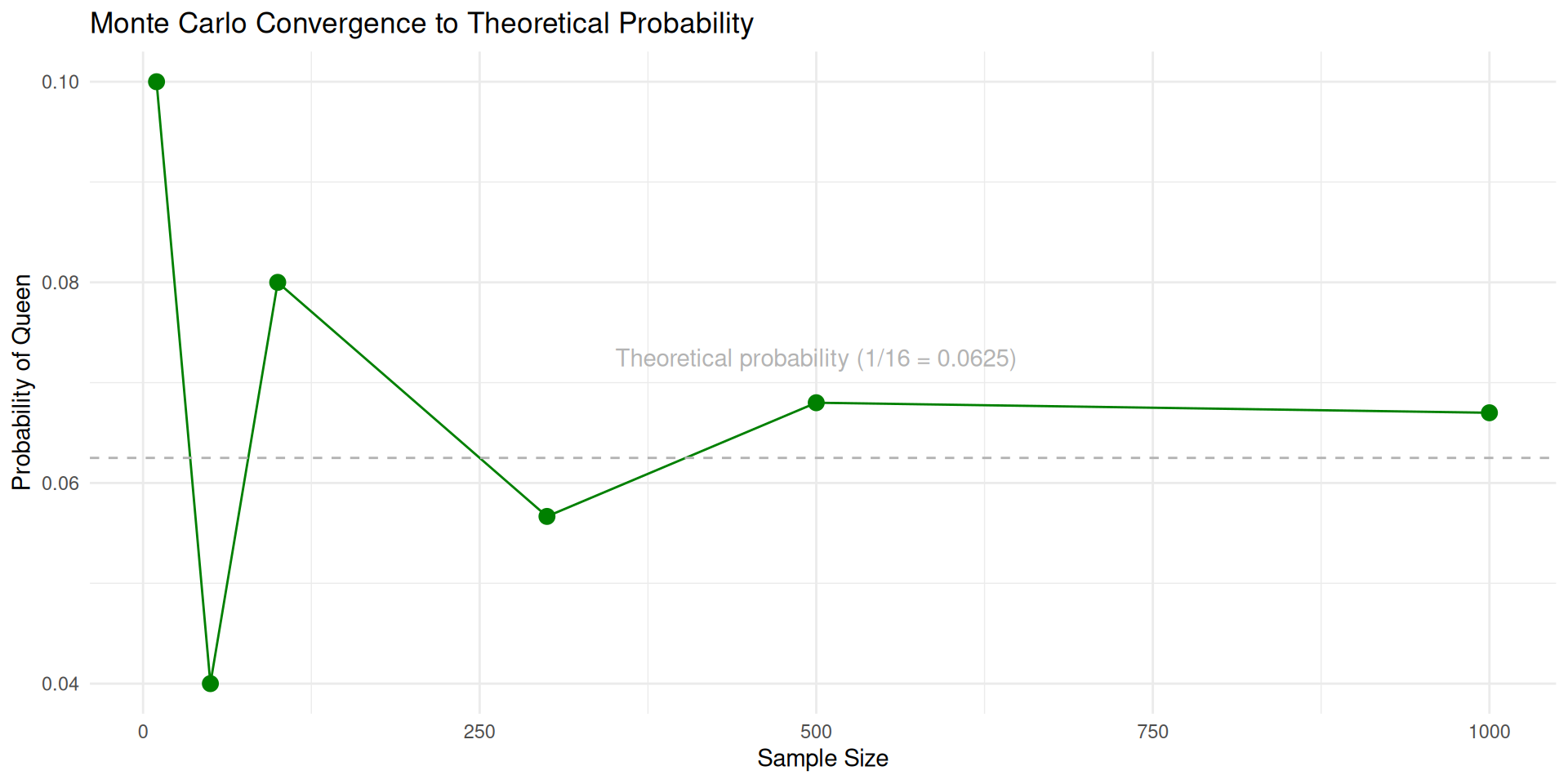
More samples → closer to the true probability. That’s the Law of Large Numbers in action.
As sample size increases, Monte Carlo estimates converge to theoretical probabilities (Law of Large Numbers). The computer does the hard work for us.
Russia, 1905


The First Markov Chain
Markov built a prediction machine with just two states:
- Start at a vowel or consonant
- Look up the transition probability to the next state
- Generate a random number to decide what happens
- Repeat
After many steps, the ratio converged to 43% vowels and 57% consonants, exactly what he counted by hand.
Dependent events following the Law of Large Numbers.
Markov Chains
A sequence of events where the probability of each event depends only on the current state.

Try it: Markov Chain Visualization
Enrico Fermi’s Innovation (1930s)
- Pioneered “statistical sampling” to model neutron diffusion
- Used simple probabilistic methods before modern computers
- Created the foundation for particle physics simulations

The Manhattan Project Connection
Back at Los Alamos, scientists were trying to figure out how neutrons behave inside a nuclear core.
A neutron can:
- Scatter off an atom and keep traveling
- Get absorbed or leave the system
- Cause fission, splitting a uranium atom and releasing two or three more neutrons
Each step depends on the previous one, it’s a Markov chain.
Ulam shared his Solitaire idea with John von Neumann, who immediately saw its power: simulate the chain on a computer.
![]()
Research Design Applications
Monte Carlo simulations help researchers make informed decisions about:
- Required sample sizes
- Minimum detectable effects
- Statistical power
- Impact of missing data
- Measurement reliability

Application 1: Sample Size Determination
Question:
What sample size do we need to detect a correlation of 0.5 between happiness and optimism?
Fixed Parameters:
- Target correlation: 0.5
- Desired power: 0.8 (80%)
- Alpha level: 0.05
- Factor loading: 0.8 (reliability of measures)
- Missing data: none
Monte Carlo Approach
- Simulate data with the target correlation
- Run tests with increasing sample sizes
- Calculate power at each sample size
- Find minimum sample size with 80% power
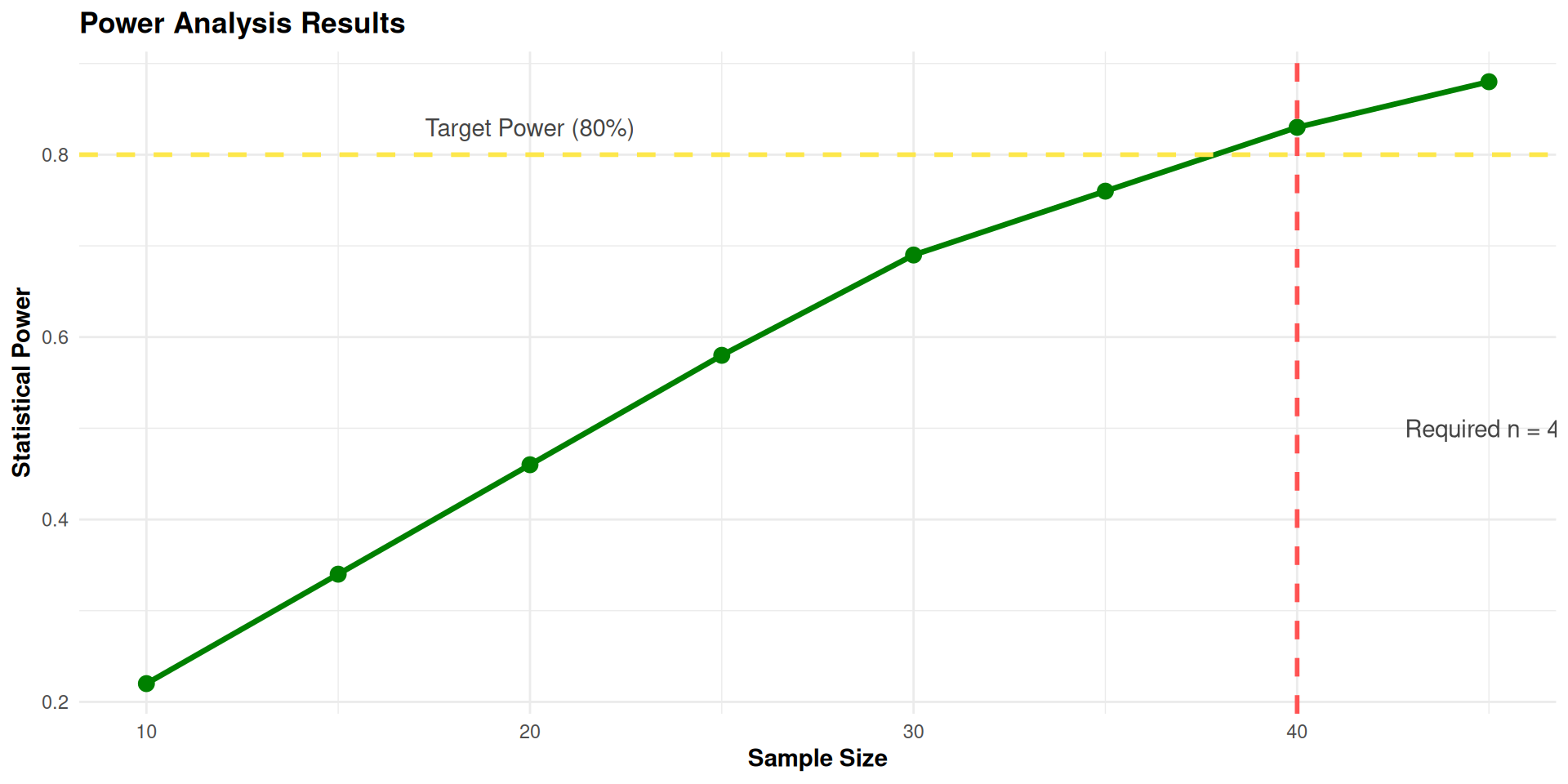
Conclusion: To detect a correlation of 0.5 with 80% power:
- Minimum required sample size: 40 participants- With this sample size, we have an 83% chance of detecting the effect if it exists
- Reliability of our measures (0.8) helps reduce the needed sample size
- Without Monte Carlo, we might have overestimated the required sample size
Application 2: Minimum Detectable Effect
Question:
What’s the smallest correlation between happiness and optimism we can reliably detect with our sample?
Fixed Parameters:
- Sample size: 40 participants (fixed by budget constraints)
- Desired power: 0.8 (80%)
- Alpha level: 0.05
- Factor loading: 0.7 (reliability of measures)
- Missing data: 5% (expected attrition)
Monte Carlo Approach
- Simulate data with various correlations
- Account for 5% missing data in simulations
- Adjust for measurement reliability (0.7)
- Find minimum correlation with 80% power
alpha <- 0.05
trials <- 1000
effective_n <- floor(40 * (1 - 0.05))
factor_loading <- 0.7
results <- tibble(correlation = seq(0.1, 0.9, by = 0.05)) |>
mutate(
adjusted_r = correlation * factor_loading^2,
sims = map(adjusted_r, \(r) {
tibble(trial = 1:trials) |>
mutate(
data = map(trial, \(t) {
MASS::mvrnorm(effective_n, mu = c(0, 0),
Sigma = matrix(c(1, r, r, 1), 2, 2)) |>
as_tibble(.name_repair = ~c("happiness", "optimism"))
}),
p_value = map_dbl(data, \(d) cor.test(d$happiness, d$optimism)$p.value)
)
}),
achieved_power = map_dbl(sims, \(s) mean(s$p_value < alpha))
) |>
select(correlation, achieved_power)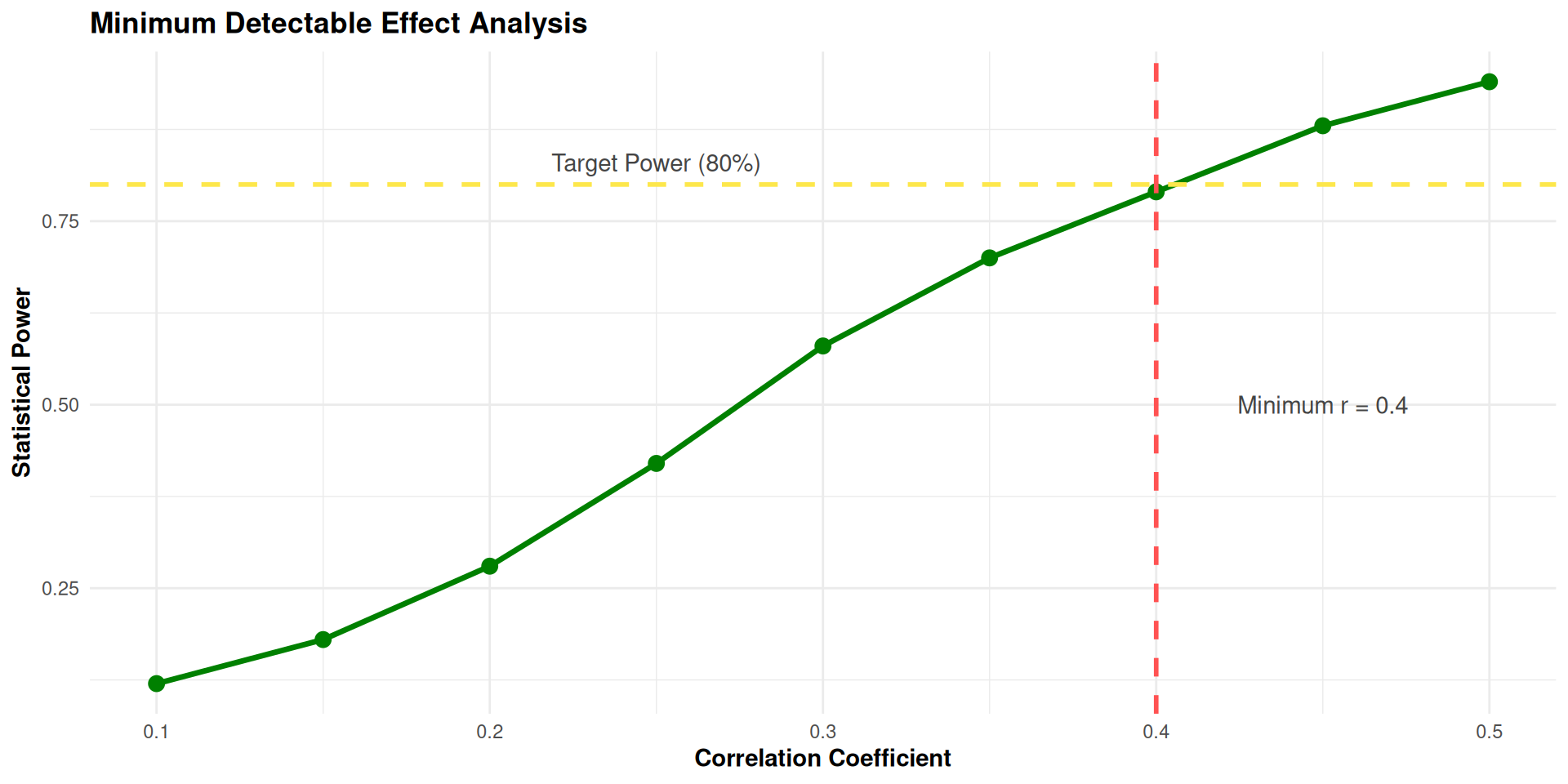
Conclusion: With 40 participants and 5% missing data:
- We can reliably detect correlations of r = 0.4 or larger- Smaller correlations (r < 0.4) will be harder to detect
- The 5% missing data reduces our effective sample size
- Measurement reliability of 0.7 further attenuates the detectable effect
- Researchers should focus on effects of at least medium size
Application 3: Power Analysis
Question:
What is our statistical power to detect a correlation of 0.3 between happiness and optimism?
Fixed Parameters:
- Sample size: 60 participants (already collected)
- Alpha level: 0.05
- Target correlation: 0.3 (small-to-medium effect)
- Factor loading: 0.62 (measured reliability)
- Missing data: 10% (actual attrition)
Monte Carlo Approach
- Simulate 1000+ datasets with our parameters
- Apply 10% missing data pattern
- Adjust for measurement reliability (0.62)
- Calculate percentage of significant results
alpha <- 0.05
trials <- 1000
effective_n <- floor(60 * (1 - 0.10))
adjusted_r <- 0.3 * 0.62^2
results <- tibble(trial = 1:trials) |>
mutate(
data = map(trial, \(t) {
MASS::mvrnorm(effective_n, mu = c(0, 0),
Sigma = matrix(c(1, adjusted_r, adjusted_r, 1), 2, 2)) |>
as_tibble(.name_repair = ~c("happiness", "optimism"))
}),
p_value = map_dbl(data, \(d) cor.test(d$happiness, d$optimism)$p.value)
)
achieved_power <- mean(results$p_value < alpha)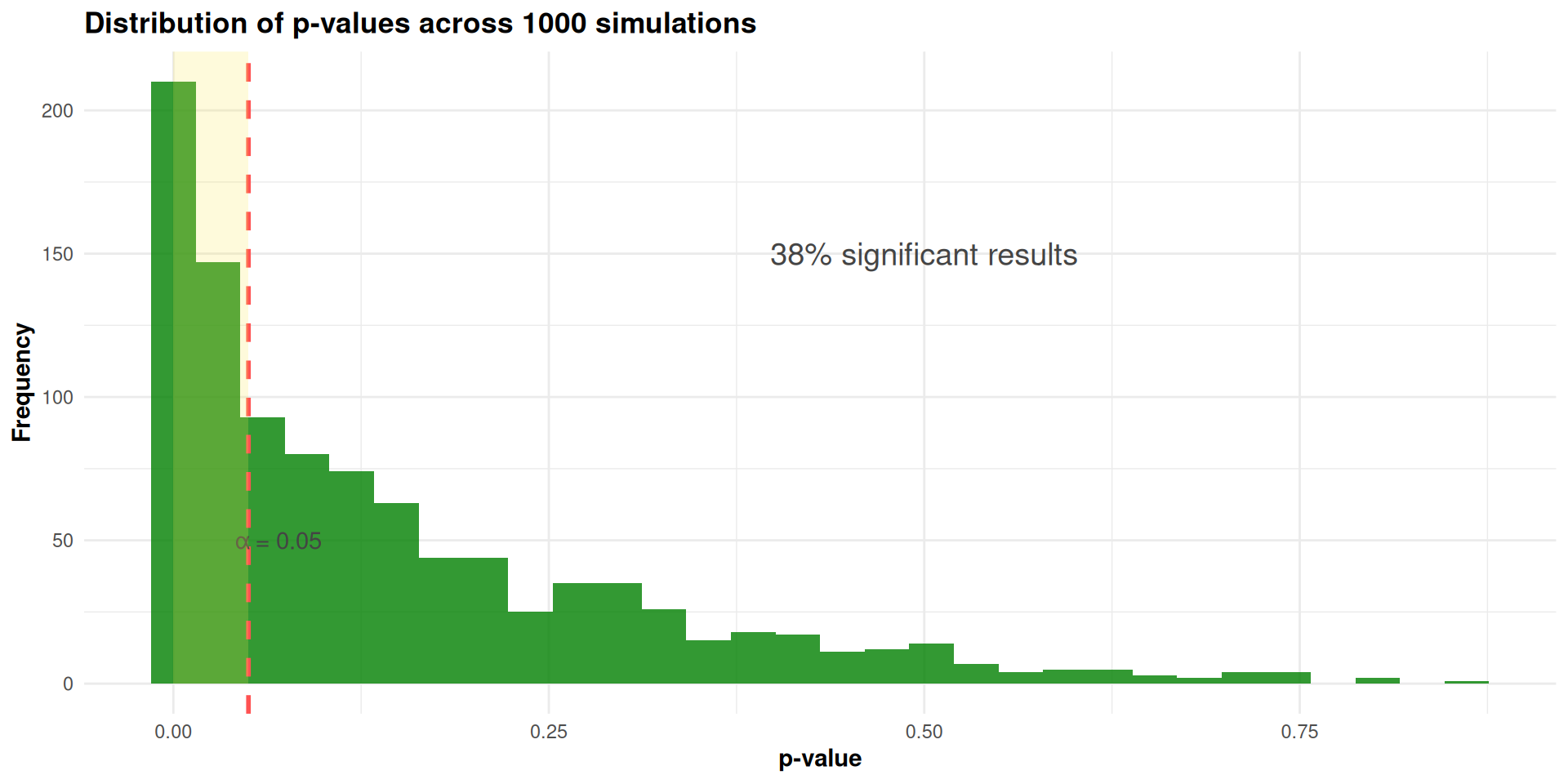
Conclusion: For our study with 60 participants:
- Statistical power is approximately 51% to detect r = 0.3
- This is below the conventional 80% power threshold
- The 10% missing data significantly reduced our power
- Measurement reliability (0.62) further attenuated the effect
- Recommendations:
- Use more reliable measures in future studies
- Implement strategies to reduce missing data
- Consider focusing on larger effect sizes
