4. Árboles de decisión
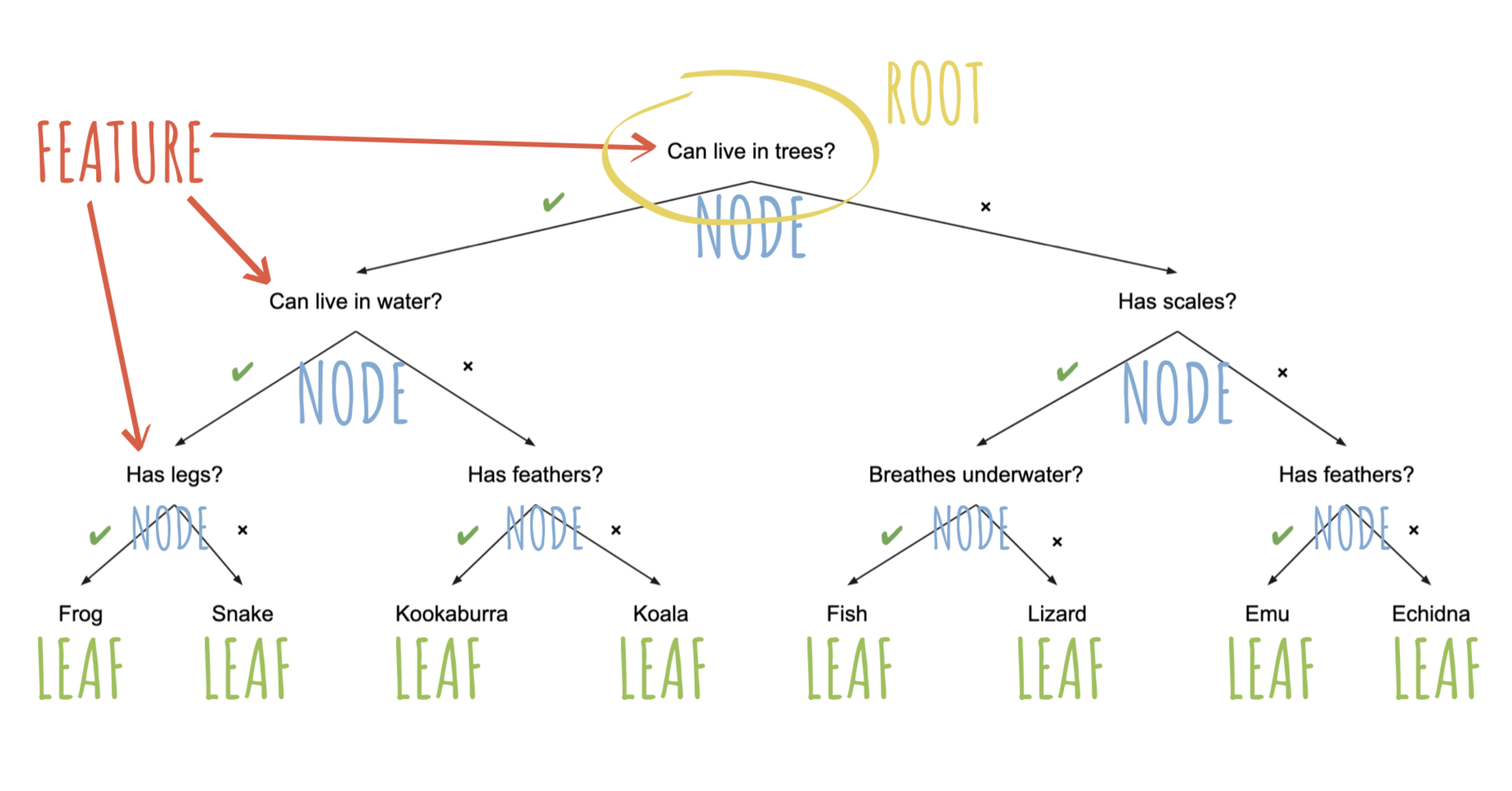
Árboles de decisión
(mejorar esto) El objetivo es tomar una serie de decisiones, basadas en las respuestas a cada pregunta, para llegar a una conclusión o predicción final. Cada nodo del árbol representa una característica de los datos que se están analizando y cada rama representa una posible respuesta a esa característica.
Los árboles de decisión son útiles porque proporcionan una forma fácil de visualizar y entender cómo se toman las decisiones en un modelo