1. Introducción a Machine Learning con tidymodels
Machine Learning
No-supervisado
No hay una variable de resultado
- Por ejemplo
- Componentes principales
- Reducción de dimensionalidad
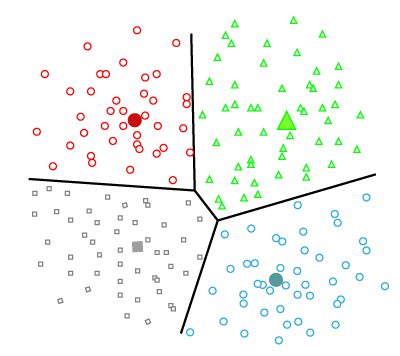
Supervisado
Hay una variable de resultado
- Regresión: variable de resultado continua
- Clasificación: variable de resultado categórica
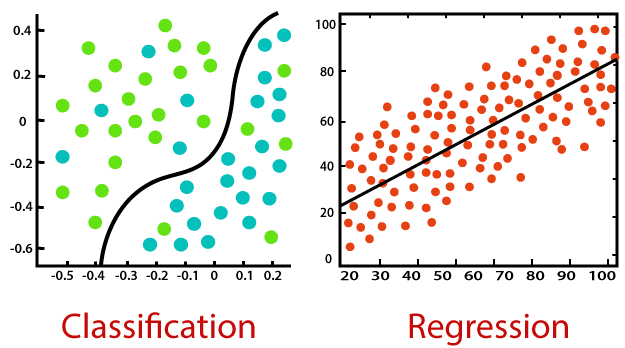
Gráfico del proceso de análisis de datos
Se inicia con importar los datos, seguido por la organización-limpieza de los datos, la exploración, la creación de modelos y finalmente la comunicación de los resultados.

imagen de R4DS
Proceso de análisis de datos
- Explorar los datos (EDA)
- Modelos iniciales
- Evaluación de los modelos
- “Ingeniería de variables”- crear nuevas variables
- Ajustar-sintonizar los modelos
- Evaluación final de los modelos
- Modelo Final
 imagen de Tidymodels
imagen de Tidymodels
¿Cuál es el mejor sofware para hacer esto?
- Python
- R
- Matlab
- Julia
- Stata
- SAS
- SPSS
- Mplus

En este workshop utilizaremos
Analizar datos en R
- Usar base R
- Usar tidyverse

Tidyverse
ggplot2 - para visualización de gráficos dplyr - para el procesamiento de datos tidyr - para la transformación de datos en formato “tidy” (ordenado) readr - para la lectura de datos en diferentes formatos (CSV, TSV, etc.) purrr - para la programación funcional tibble - para la creación de data frames en formato “tidy” stringr - para la manipulación de cadenas de texto forcats- para la manipulación de factores más
Tidymodels
parsnip - para la especificación de modelos recipes - para la preparación de datos rsample - para la validación de modelos tune - para la sintonización de hiperparámetros workflows - para la creación de flujos de trabajo dials - para la selección de hiperparámetros yardstick - para la evaluación de modelos más
